Проверка смарт диска. Исправляем ошибки S.M.A.R.T
Что такое S.M.A.R.T.? Почему возникают SMART ошибки и о чем это говорит? Ниже мы детально расскажем про причины и методы устранения подобных проблем.
Средство S.M.A.R.T. , показывающее ошибки жесткого диска (HDD или SSD) является сигналом того, что с накопителем случились какие-то неполадки, влияющие на стабильность и работу компьютера.
Помимо этого, такая ошибка – серьезный повод задуматься о сохранности своих важных данных , поскольку из-за проблемного накопителя можно попросту лишиться всей информации, которую практически невозможно восстановить .
Что такое SMART и что он показывает?
«S.M.A.R.T.»
расшифровывается как «self-monitoring, analysis and reporting technology»
, что в переводе означает «технология самодиагностики, анализа и отчетности»
.
Каждый жесткий диск, подключённый через интерфейс SATA или ATA, имеет встроенную систему S.M.A.R.T., которая позволяет выполнять следующие функции:
- Проводить анализ накопителя.
- Исправлять программные проблемы с HDD.
- Сканировать поверхность жесткого диска.
- Проводить программное исправление , очистку или замену поврежденных блоков.
- Выставлять оценки жизненноважным характеристикам диска.
- Вести отчётность о всех параметрах жесткого диска.
Система S.M.A.R.T. позволяет давать пользователю полную информацию о физическом состоянии жесткого диска методом выставления оценок, при помощи которых можно рассчитать примерное время выхода HDD из строя. С данной системой можно лично ознакомиться, воспользовавшись программой Victoria или другими аналогами.
С тем, как работать, проверять и исправлять ошибки жесткого диска в программе Victoria, Вы можете ознакомиться в статье « ».
Ошибки S.M.A.R.T.
Как правило, в нормально работающем накопителе система S.M.A.R.T. не выдает никаких ошибок даже при невысоких оценках. Это обусловлено тем, что появление ошибок является сигналом возможной скорой поломки диска .
Ошибки S.M.A.R.T. всегда свидетельствуют о какой-либо неисправности или о том, что некоторые элементы диска практически исчерпали свой ресурс . Если пользователю стали демонстрироваться подобные сообщения, следует задуматься о сохранности своих данных, поскольку теперь они могут исчезнуть в любой момент !
Примеры ошибок SMART
Ошибка «SMART failure predicted»

В данном случае S.M.A.R.T. оповещает пользователя о скором выходе диска из строя . Важно: если Вы увидели такое сообщение на своем компьютере, срочно скопируйте всю важную информацию и файлы на другой носитель, поскольку данный жесткий диск может прийти в негодность в любой момент !
Ошибка «S.M.A.R.T. status BAD»
Данная ошибка говорит о том, что некоторые параметры жесткого диска находятся в плохом состоянии (практически выработали свой ресурс). Как и в первом случае, следует сразу сделать бекап важных данных .
Ошибка «the smart hard disk check has detected»
Как и в двух предыдущих ошибках, система S.M.A.R.T. говорит о скорой поломке HDD .
Коды и названия ошибок могут различаться в разных жестких дисках, материнских платах или версиях BIOS, тем не менее, каждая из них является сигналом для того, чтобы сделать резервную копию своих файлов .
Как исправить SMART ошибку?
Ошибки S.M.A.R.T. свидетельствуют о скорой поломке жесткого диска , поэтому исправление ошибок, как правило, не приносит должного результата, и ошибка остается. Помимо критических ошибок, существуют еще и другие проблемы, которые могут вызывать сообщения такого рода. Одной из таких проблем является повышенная температура носителя .
Ее можно посмотреть в программе Victoria во вкладке SMART под пунктом 190 «Airflow temperature»
для HDD. Или под пунктом 194 «Controller temperature»
для SDD.
Если данный показатель будет завышен, следует принять меры по охлаждению системного блока :
- Проверить работоспособность кулеров .
- Очистить пыль .
- Поставить дополнительный кулер для лучшей вентиляции.
Другим способом исправления ошибок SMART является проверка накопителя на наличие ошибок .
Это можно сделать, зайдя в папку «Мой компьютер» , кликнув правой клавишей мыши по диску или его разделу, выбрав пункт «Сервис» и запустив проверку.

Если ошибка не была исправлена в ходе проверки, следует прибегнуть к дефрагментации диска .
Чтобы это сделать, находясь в свойствах диска, следует нажать на кнопку «Оптимизировать» , выбрать необходимый диск и нажать «Оптимизировать» .

Если ошибка не пропадет после этого, скорее всего, диск просто исчерпал свой ресурс , и в скором времени он станет нечитаемым , а пользователю останется только приобрести новый HDD или SSD.
Как отключить проверку SMART?
Диск с ошибкой S.M.A.R.T. может выйти из строя в любой момент , но это не означает, что им нельзя продолжать пользоваться.
Стоит понимать, что использование такого диска не должно подразумевать в себе хранение на нем сколько-либо стоящей информации. Зная это, можно провести сброс smart настроек , которые помогут замаскировать надоедливые ошибки.
Для этого:
Шаг 1. Заходим в BIOS или UEFI (кнопка F2 или Delete во время загрузки), переходим в пункт «Advanced» , выбираем строку «IDE Configuration» и нажимаем Enter . Для навигации следует использовать стрелочки на клавиатуре.

Шаг 2. На открывшемся экране следует найти свой диск и нажать Enter (жесткие диски подписаны «Hard Disc»).

Шаг 3. Опускаемся вниз списка и выбираем параметр SMART , нажимаем Enter и выбираем пункт «Disabled» .

Шаг 4. Выходим из BIOS , применяя и сохраняя настройки .
Стоит отметить, на некоторых системах данная процедура может выполняться немного по-другому, но сам принцип отключения остается прежним.
После отключения SMART ошибки перестанут появляться , и система будет загружаться в штатном порядке до тех пор, пока HDD окончательно не выйдет из строя . В некоторых ситуациях ошибки могут показываться в самой ОС, тогда достаточно несколько раз отклонить их, после чего появится кнопка «Больше не показывать» .
Что делать если данные были утеряны?
При случайном форматировании, удалении вирусами или утере любых важных данных следует быстро вернуть утерянную информацию самым эффективным методом.
Одним из таких методов является программа для восстановления данных RS Partition Recovery . Данная утилита сможет быстро вернуть удаленные фотографии , видеофайлы , звуковые дорожки , картинки , документы и любые другие файлы , которые исчезли с накопителя по различным причинам. имеет продвинутую систему сканирования и поиска удаленной информации, что позволяет находить и восстанавливать даже те файлы, которые были удавлены достаточно давно. Детальнее с возможностями и главными особенностями RS Partition Recovery можно ознакомиться на официальном сайте производителя
Технология S.M.A.R.T. родилась в далеком 1995 году, так что возраст у нее почтенный. Предполагалось, что атрибуты SMART (давайте для простоты писать аббревиатуру без точек), формируемые микропрограммой жесткого диска, позволят программно оценивать состояние накопителя, а также дадут механизм для предсказания выхода его из строя. Последнее в те времена было достаточно актуально: срок жизни дисков в серверах, например, исчислялся годом-полутора, и знать, когда готовить замену, было нелишним.
Со временем многое поменялось: что-то отмерло, какие-то стороны развились сильнее (например, контроль механики диска). Первоначальный набор из десятка простейших атрибутов усложнился и разросся в несколько раз, порой менялся их смысл, многие производители ввели собственные атрибуты с не всегда ясным функционалом. Появилась масса программ для анализа SMART (как правило, невысокого качества, но с эффектным интерфейсом, да еще и за деньги) и т.п.
Так что не мешает описать современное состояние SMART. Начнем с критически важных атрибутов, ухудшение которых почти всегда свидетельствует о проблемах с накопителем. Именно их первым делом смотрят ремонтники при диагностике HDD.
- #01 Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных ДО выдачи в интерфейс; на пугающе огромные цифры можно не обращать внимания.
- #03 Spin-Up Time — время раскрутки пакета пластин из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т.п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
- #05 Reallocated Sectors Count — число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор переназначенным и переносит данные в резервную область. Вот почему на современных HDD нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, на жаргоне — ремап. Поле Raw Value атрибута содержит общее количество переназначенных секторов. Чем оно больше, тем хуже состояние поверхности диска.
- #07 Seek Error Rate — частота ошибок при позиционировании блока магнитных головок (БМГ). Рост этого атрибута свидетельствует о низком качестве поверхности или о поврежденной механике накопителя. Также может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
- #10 Spin-Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута растет, то велика вероятность проблем с механикой.
- #196 Reallocation Event Count — число операций переназначения. В поле Raw Value атрибута хранится общее число попыток переноса информации со сбойных секторов в резервную область диска (она, как правило, не слишком велика — несколько тысяч секторов). Учитываются как успешные, так и неудачные операции.
- #197 Current Pending Sector Count — текущее число нестабильных секторов. Здесь хранится число секторов, являющихся кандидатами на замену. Они не были еще определены как плохие, но считывание с них происходит с затруднениями (например, не с первого раза). Если «подозрительный» сектор будет в дальнейшем считываться успешно, то он исключается из числа кандидатов. В случае же повторных ошибочных чтений накопитель попытается восстановить его и выполнить ремап.
- #198 Uncorrectable Sector Count — число секторов, при чтении которых возникают неисправимые (внутренними средствами) ошибки. Рост этого атрибута указывает на серьезные дефекты поверхности или на проблемы с механикой накопителя.
- #220 Disk Shift
— сдвиг пакета пластин относительно оси шпинделя. В основном возникает из-за сильного удара или падения диска. Единица измерения неизвестна, но при сильном росте атрибута диск не жилец.
Также следует принимать во внимание и информационные атрибуты , способные много чего поведать об «истории» диска.
- #02 Throughput Performance — средняя производительность диска. Если значение атрибута уменьшается, то велика вероятность, что у накопителя есть проблемы.
- #04 Start/Stop Count — число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счетчик включения режима энергосбережения.
- #08 Seek Time Performance — средняя производительность операции позиционирования головок. Снижение значения этого атрибута свидетельствует о неполадках в механике привода головок (в первую очередь о замедленном позиционировании).
- #09 Power-On Hours (POH) — время, проведённое во включенном состоянии. Показывает общее время работы диска, единица измерения зависит от модели (не только 1 час, но и 30 мин, и даже 1 минута).
- #11 Recalibration Retries — число повторов рекалибровки в случае, если первая попытка была неудачной. Рост этого атрибута указывает на проблемы с механикой диска.
- #12 Device Power Cycle Count — число полных циклов включения-выключения диска.
- #13 Soft Read Error Rate — частота появления «программных» ошибок при чтении данных. Сюда можно отнести ошибки программного обеспечения, драйверов, файловой системы, неверную разметку диска — в общем, почти все, что не относится к аппаратной части.
- #190 Airflow Temperature — температура воздуха внутри корпуса HDD. Для дисков Seagate атрибут выдается в нормировке 100º минус температура (тем самым критический нагрев соответствует значению 45), а модели Western Digital используют нормировку 125º минус температура.
- #191 G - sense error rate — число ошибок, возникших из-за внешних нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
- #192 Power - off retract count — число зафиксированных повторов включения/выключения питания накопителя.
- #193 Load/Unload Cycle Count — число циклов перемещения БМГ в специальную парковочную зону/в рабочее положение.
- #194 HDA temperature — температура механической части диска, в просторечии банки (HDA — Hard Disk Assembly). Информация снимается со встроенного термодатчика, которым служит одна из магнитных головок, обычно нижняя в банке. В битовых полях атрибута фиксируются текущая, минимальная и максимальная температура. Не все программы, работающие со SMART, правильно разбирают эти поля, так что к их показаниям стоит относиться критично.
- #195 Hardware ECC Recovered — число ошибок, скорректированных аппаратной частью диска. Сюда входят ошибки чтения, ошибки позиционирования, ошибки передачи по внешнему интерфейсу. На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону.
- #199 UltraDMA (Ultra ATA) CRC Error Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера.
- #200 Write Error Rate/ Multi-Zone Error Rate — частота появления ошибок при записи данных. Показывает общее число ошибок записи на диск. Чем больше значение атрибута, тем хуже состояние поверхности и механики накопителя.
Как видим, большинство «интересных» атрибутов отражает функционирование механики накопителя. Технология SMART действительно позволяет предсказывать выход диска из строя в результате механических неисправностей, что, по статистике, составляет около 60% всех отказов. Полезен и мониторинг температур: перегрев головок резко ускоряет их деградацию, так что превышение опасного порога (45-55º в зависимости от модели) — сигнал срочно улучшить охлаждение диска.
Вместе с тем не следует переоценивать возможности SMART. Современные диски нередко «дохнут» на фоне отличных атрибутов, что связано с тонкими процессами дефект-менеджмента в условиях высокой плотности записи и не всегда, мягко говоря, качественных компонентов (разнобой в отдаче головок сегодня — обычное дело). Тем более SMART не способен предсказать последствия таких «форс-мажоров», как скачок напряжения, перегрев платы электроники или повреждение накопителя от удара.
Практически у всех атрибутов наибольший интерес представляет поле Raw Value: «сырые» значения наиболее информативны. Их нормировка (степень приближения к абстрактному порогу) часто ничего не дает и только запутывает дело. Поэтому и программы, полагающиеся на эти проценты, нельзя считать вполне надежными. Типичный случай для них — ложные тревоги. Программа сообщает, что новый, недавно установленный накопитель того и гляди «склеит ласты». А все дело в том, что в начале эксплуатации некоторые атрибуты SMART быстро меняются и примитивная экстраполяция приводит к пугающим пользователя прогнозам.
Я советую бесплатную программу HDDScan— она корректно понимает все атрибуты, в том числе и новые, правильно разбирает температурные показатели. Отчет выводится в виде аккуратной xml-таблицы с цветовой индикацией, которую можно сохранить или распечатать.
SMART диска WD пятилетнего возраста. О его близкой кончине свидетельствуют ненулевые значения атрибутов 1 и 200 (для WD они особенно чреваты), а также тот факт, что после ремапа атрибут 197 снова растет. Это значит, что возможности исправления дефектов исчерпаны
Крайне полезна у HDDScan возможность считывать SMART у внешних накопителей, столь распространенных сегодня. Практически ни одна другая программа этого не умеет, ведь на пути данных стоит контроллер, преобразующий интерфейс PATA/SATA в USB или FireWire. Автор целенаправленно работал в этом направлении, и ему удалось охватить широкий спектр контроллеров. Не забыты и диски с интерфейсом SCSI, до сих пор широко применяемые в серверах (атрибуты у них особые — например, выводится общее число записанных или считанных байтов за всю жизнь накопителя).
Функционал HDDScan полностью отвечает потребностям ремонтника. Когда первичную диагностику принесенного внешнего диска можно провести, не разбирая корпус, — это удобно, экономит время, а порой и сохраняет гарантию.

SMART, снятый со SCSI-диска. Здесь исторически сложились совсем другие атрибуты
⇡ Барьеры HDD
Механика давно стала ахиллесовой пятой HDD, и даже не столько из-за чувствительности к ударам и вибрации (это еще можно компенсировать), сколько из-за медлительности. Самые быстрые «дерганья» блоком магнитных головок (2-3 мс у лучших серверных моделей) в тысячи раз уступают скоростям электроники.
И принципиально ничего тут не улучшишь. Поднимать скорость вращения пакета дисков некуда, 15000 об./мин уже предел. Японцы несколько лет назад подступались к 20000 об./мин (вполне гироскопная скорость), но в итоге отказались — не выдерживают материалы, конструкция получается слишком дорогая и для массового производства слабо пригодная. В малых же сериях винчестеры выйдут золотыми, такие никто не купит — это не гироскопы, которые заменить нечем.
Выходит, уткнулись в барьер. Механику на кривой козе не объедешь. Единственный выход — поднимать плотность записи, поперечную и продольную. Продольная плотность (вдоль дорожки) влияет на производительность накопителя, т.е. на поток данных к остальным узлам компьютера. Но все равно, даже достигнутые 100-130 Мбайт/с — это для нынешних компьютеров слишком мало. Например, рядовая оперативная память (DRAM) имеет реальную производительность около 3 Гбайт/с, а кеш процессора — еще больше. Разница на порядки, и она сильно сказывается на общем быстродействии. Конечно, никто не требует от энергонезависимого накопителя, емкость которого в сотни раз превышает DRAM, такой же производительности. Но даже простое удвоение было бы заметно любому пользователю.
Поперечная плотность записи — это густота дорожек на пластине, в современных HDD она превышает 10000 на 1 миллиметр. Получается, что сама дорожка имеет ширину менее 100 нм (между прочим, нанотехнологии в чистом виде). Это позволяет резко поднять емкость в расчете на одну поверхность, а также ускоряет позиционирование за счет изощренных алгоритмов (их разработка потянула бы на пару докторских диссертаций).
Как итог, за последние годы емкость и производительность HDD значительно выросли. Все это стало возможным благодаря технологии перпендикулярной записи, которая существует уже более 20 лет, но до массового внедрения дозрела только в 2007 году. Причем емкость тогда выросла даже сильнее, чем требуется: первые терабайтные диски встретили вялый отклик пользователей. Народ просто не понимал, куда приспособить таких монстров, тем более что они поначалу строились на пяти пластинах, были капризными, шумными и горячими (речь о тогдашних флагманах Hitachi).
Потом, конечно, люди разобрались, торренты заработали в полную силу, да и количество пластин поуменьшилось. В то же время плотность записи выросла до 500-750 Гбайт на пластину (имеются в виду диски настольного сегмента с форм-фактором 3,5″). Вот-вот в массовое производство пойдут терабайтные пластины, что даст возможность выпустить винчестеры объемом до 4 Тбайт (больше четырех пластин в стандартном корпусе высотой 26,1 мм не уместить; хитачевские пятипластинные первенцы большого развития не получили).

Трехтерабайтный диск WD Caviar Green WD30EZRX, наиболее емкий на сегодня. Имеет четырехпластинный дизайн, выпускается ровно год (с 20 октября 2010 г.). Как полагается, весной и летом дешевел, но в последние дни резко подорожал из-за наводнения в Таиланде (там расположены сборочные заводы WD, и стихия блокировала подвоз комплектующих)
Увы, скорость позиционирования выросла, мягко говоря, несильно, а у массовых моделей так вообще осталась на прежнем уровне, а то и упала в угоду… тишине. Маркетологи доказали, что потребитель голосует кошельком за гигабайты в расчете на один доллар, а не за миллисекунды доступа. Поэтому и небыстры дешевые диски по сравнению с породистыми серверными собратьями. Медлительность хорошо проявляется в скорости загрузки ОС, когда надо читать с диска большое количество мелких файлов, разбросанных по пластинам. Здесь главную роль играет скорость вращения шпинделя и мощный привод БМГ, дающий возможность больших ускорений.
Между прочим, «быстрые» диски легко отличить даже на вес — они заметно тяжелее «медленных». Полноразмерная банка с утолщенными стенками, способствующая геометрической стабильности и подавлению вибраций, скоростной шпиндельный двигатель, мощные магниты позиционера, двухслойная крышка повышенной жесткости — все это прибавляет такому накопителю десятки и сотни граммов. Еще больше отрыв в серверных моделях на 15000 об./мин, где пластины уменьшенного размера окружены внушительным объемом литого алюминия, а общий вес «харда» доходит до килограмма.

Высокопроизводительный диск WD Raptor со скоростью вращения шпинделя 10 000 об./мин. При емкости 150 Гбайт весит 740 г (массовые модели той же емкости — 400-500 г). Обратите внимание на размер магнитов и толщину стенок
С удешевлением твердотельных SSD, использующихся, в первую очередь, под операционную систему, нужда в высокопроизводительных HDD стала снижаться, а сами они постепенно выделяются в особый сегмент рынка (такова, например, «черная» серия у WD). Подобными дисками комплектуются профессиональные рабочие станции с ресурсоемкими приложениями, критичными к скорости доступа. Рядовые же пользователи брать достаточно дорогие накопители не торопятся, предпочитая объем производительности.
На другом конце спектра — популярные «зеленые» модели с намеренно замедленным вращением шпинделя (5400-5900 об./мин вместо 7200) и небыстрым позиционированием головок. Дешевые, тихие, холодные и достаточно надежные, эти винчестеры идеально подходят для хранения мультимедийных данных в домашних компьютерах, внешних корпусах и сетевых хранилищах. На наших прилавках все эти Green и LP сильно потеснили другие линейки, так что в мелких «точках» порой ничего больше и не найдешь.
⇡ Расточительность магнитной записи
Намагниченность доменов жесткого диска, как и в середине двадцатого века, меняют с помощью магнитной головки, поле которой возбуждается переменным электрическим током и действует на магнитный слой через зазор. Также эта технология требует быстрого вращения пластин, прецизионного контроля положения головки и т.д. Двигатель и позиционер жесткого диска, а также управляющая ими электроника потребляют заметную мощность, да и стоят немало. Но главное — на само возбуждение магнитного поля тратится очень много энергии.
Расточительность стандартного метода магнитной записи трудно оценить, работая на персональном компьютере. Жесткие диски массовых серий даже при активной работе потребляют менее 10 Вт, что на фоне прочих комплектующих (100 Вт и более) почти незаметно. Но ваши взгляды сразу переменятся после посещения серверной комнаты какого-нибудь крупного банка, а чтобы получить впечатлений на всю оставшуюся жизнь, достаточно подойти к дисковой стойке суперкомпьютера. В шуме сотен и тысяч жестких дисков, обдувающих их вентиляторов и прецизионных кондиционеров становится понятно, сколько энергии в глобальном масштабе тратится на такую работу.
Недаром для систем хранения данных энергоэффективность в списке характеристик выходит на первый план. Вот уже и Google переводит свои дата-центры на баржи в море (вот где настоящие офшоры!). Оказывается, охлаждение СХД забортной водой радикально сокращает операционные затраты, в первую очередь за счет экономии на кондиционерах.
⇡ О питании жестких дисков
Будет ли работать обычная 220-вольтовая лампочка от 230 В? Конечно, будет. А от 240 В? Тоже. Вопрос — сколько она протянет? Понятно, что меньше или существенно меньше — это зависит от конкретной лампочки. Ей суждена яркая, но короткая жизнь.
Примерно та же ситуация и с жесткими дисками. Наивные производители проектировали их, полагаясь на стандартные +5 В и +12 В. Однако в типичном компьютерном блоке питания (БП) стабилизируется лишь линия 5 В. К чему же это приводит?
При высокой нагрузке на процессор (а современные «камни» потребляют немало) и недостаточной мощности БП линия 5 В проседает, и система стабилизации отрабатывает это дело, повышая напряжение до номинального значения. Одновременно повышается и напряжение 12 В (из-за отсутствия стабилизации по нему). В результате и так нестойкий к нагреву HDD работает еще и при повышенном напряжении, которое подается на самые греющиеся узлы — микросхему управления двигателем (на жаргоне ремонтников — «крутилка») и привод головок (т.н. «звуковая катушка»). Итог — смотри рассуждение о лампочке.


Сгоревшая «крутилка» на плате как результат повышенного напряжения и плохого охлаждения. Нередко микросхема сгорает в буквальном смысле, с пиротехническими эффектами и выгоранием дорожек на плате. Такое ремонту не подлежит
Отсюда советы по блоку питания. Чем больше его мощность, тем лучше (в разумных пределах: запас более 30-35% по отношению к реальному потреблению снижает КПД блока, так что вы будете греть комнату). Менее мощный, но фирменный БП лучше более мощного, но безродно-китайского. Помните — разгоняют не только процессоры. В первом приближении, 420 «китайских» ватт эквивалентны 300 «правильным».
По-хорошему, надо бы еще учитывать возраст БП: после 2-3 лет эксплуатации его реальная мощность заметно снижается, а выходные напряжения дрейфуют. Разумеется, в некачественных изделиях, работающих на честном китайском слове, процессы старения выражены гораздо резче. Хорошо еще, если подобный блок тихо умрет сам, а не утащит за собой в агонии половину системного блока!
Максимально допустимым считается 12,6 В (+5% от номинала). Однако у многих дисков c ростом напряжения наблюдается нелинейно-резкий нагрев упомянутых выше узлов — «крутилки» и «катушки». Поэтому я рекомендую строже контролировать БП с помощью внешнего вольтметра (датчики на материнской плате, измеряющие напряжение для BIOS и программ типа AIDA, могут быть весьма неточны).
Измерять напряжение лучше всего на разъемах Molex и обязательно под полной нагрузкой: процессор занят вычислениями с плавающей точкой, видеокарта — выводом динамичной трехмерной графики, а диск — дефрагментацией. При 12,2-12,4 В стоит призадуматься, 12,4-12,6 В — поволноваться, 12,6-13 В — бить тревогу, а в случае 13 В и выше — копить деньги на новый диск или положить гарантийный талон на видное место…

Конденсаторы (2200 мкФ, 25 В), напаянные на цепи питания HDD (желтый провод — +12 В, красный — +5 В, черный — земля). В данном случае они уменьшают пульсации напряжения, от которых блок питания издает раздражающий высокочастотный писк
Если напряжение по линии 12 В сильно завышено, а вы не боитесь паяльника и способны отличить транзистор от диода, то можете включить последний в разрыв питания HDD (напомню, линии 12 В соответствует желтый провод). Диод сыграет роль ограничителя — на его p-n переходе упадут «лишние» 0,2-0,7 В (в зависимости от типа диода), и диску станет полегче. Только диод надо брать достаточно мощный, чтобы он выдерживал пусковой ток в 2-3 А.
И без фанатизма: результирующее напряжение не должно опускаться ниже 11,7 В. В противном случае возможна неустойчивая работа диска (множественные рестарты) и даже порча данных. А некоторые модели (в частности, Seagate 7200.10 и 7200.11) могут вообще не запуститься.
⇡ Миграция с флеш
Память NAND Flash появилась много позднее, чем HDD, и переняла ряд его технологий — взять хотя бы коды ECC. Далее оба направления развивались параллельно и сравнительно независимо. Но в последнее время наметился и обратный процесс: миграция технологий с флеш-памяти на жесткие диски. Конкретно речь идет о выравнивании износа.
Как известно, любой флеш-чип имеет ограниченный ресурс по числу стираний-записей в одну ячейку. В какой-то момент стереть ее уже не удается, и она навсегда застывает с последним записанным значением. Поэтому контроллер считает количество записей в каждую страницу и в случае превышения копирует ее на менее изношенное место. В дальнейшем вся работа ведется с новым участком (этим заведует транслятор), а старая страница остается как есть и не используется. Данная технология получила название Wear Leveling. Так вот, износ есть и в жестких дисках, но там он механический и температурный. Если магнитная головка все время висит над одной дорожкой (скажем, постоянно изменяется тот или иной файл), то растет вероятность повреждения дорожки при случайных толчках или вибрации диска (например, от соседних накопителей в корзине). Головка может коснуться пластины и повредить магнитный слой со всеми вытекающими печальными последствиями. Даже если вредного контакта нет, неподвижная головка локально нагревается и пусть обратимо, но деградирует. Запись в данное место происходит менее надежно, растет вероятность последующего неустойчивого считывания (а при современных огромных плотностях записи любое отклонение параметров губительно).
Эти соображения достаточно очевидны, и прошивка серверных дисков с интерфейсом SCSI/SAS (а они весьма горячи) давно научилась перемещать головки в простое, дабы они не перегревались. Но еще лучше вместе с головкой «перебрасывать» и информацию по пластине — в этом случае описанные эффекты подавляются максимально, а надежность накопителя растет. Вот Western Digital и ввел подобный механизм в новых моделях VelociRaptor. Это дорогие высокопроизводительные диски со скоростью вращения шпинделя 10000 об./мин и пятилетней гарантией, так что Wear Leveling там уместен.


VelociRaptor снаружи и внутри. Привлекает внимание мощный радиатор. Пластины же имеют уменьшенный диаметр — это характерно для современных скоростных дисков.
Кроме того, вся линейка VelociRaptor нацелена на использование в высоконагруженных системах, в первую очередь серверах, где запись на диск ведется очень интенсивно и зачастую в одни и те же файлы (типичный пример — логи транзакций). Массовым «ширпотребным» дискам высокие нагрузки не грозят, греются они тоже умеренно, так что подобный изыск там вряд ли появится. Впрочем, поживем — увидим.
⇡ Аdvanced Format и его применение
Вот уже более 20 лет все жесткие диски имеют одинаковый размер физического сектора: 512 байт. Это минимальная порция записи на диск, позволяющая гибко управлять распределением дискового пространства. Однако с ростом объема HDD все сильнее стали проявляться недостатки такого подхода — в первую очередь неэффективное использование емкости магнитной пластины, а также высокие накладные расходы при организации потока данных.
Поэтому диски большой емкости (терабайт и выше) стали производиться по технологии Advanced Format , которая оперирует «длинными» физическими секторами в 4096 байт. Разметка магнитных пластин под AF весьма выгодна для производителя: меньше межсекторных промежутков, выше полезная емкость дорожки и всей пластины (а это, наряду с магнитными головками, самый дорогой компонент HDD). Именно Advanced Format позволил выпустить на рынок недорогие винчестеры, столь популярные ныне у потребителей аудио- и видеоконтента. AF-дисками емкостью 1-3 Тбайт комплектуются не только компьютеры, но и масса внешних накопителей, сетевых хранилищ и медиаплееров.

Один из первых дисков 3,5″ с Advanced Format, выпущенный в 2009 г
Но даром ничего не дается, новые диски уже начинают приносить в ремонт. Похоже, надежность все-таки просела. Ведь единичный сбой диска или дефект поверхности портит теперь в 8 раз больше данных пользователя, чем обычно. При физическом секторе в 4 Кбайт и эмуляции «коротких» секторов в 512 байт не будет читаться от 1 до 8 секторов. Операционная система на это реагирует понятно как: авария, все пропало! В итоге мелкая проблема на пластинах вырастает для пользователя в зависание или чего еще хуже.
Я считаю, на дисках с AF не стоит держать ОС, прикладные программы и базы данных со множеством мелких файлов. Пока что их удел — мультимедийные данные, некритичные к выпадениям.
В первую очередь рекомендую заглянуть на форум HARDW.net . Его раздел «Накопители информации» посещает множество профессиональных ремонтников и энтузиастов (почти 40 тыс. участников). Там можно найти ответы практически по любой теме, связанной с HDD, за исключением самых новых «нераскопанных» моделей. Начните с подраздела «Песочница»: на простые (в понимании профессионалов) вопросы там отвечают подробно и содержательно, а не отшивают, как в других местах, — «несите к ремонтнику».
Еще больше информации, правда, на английском языке, можно найти на портале HDDGURU . Помимо ремонтно-диагностического ПО и статей по отдельным вопросам (например, как поменять головки у диска), там есть международный форум ремонтников, а также огромный архив ресурсов по HDD (firmware, документация, фото и т.п.). Портал прививает широкий взгляд на вещи, он будет интересен подготовленным и мотивированным людям. Во всяком случае, в закрытых конференциях ремонтников ссылки на него пробегают постоянно.
Сошлюсь и на свою статью «Как продлить жизнь жестким дискам» в трех частях. Она дает начальные сведения по обращению с HDD, и хотя написана более трех лет назад, устарела мало — диски за это время принципиально не изменились, разве что стали еще менее надежными из-за свирепой экономии. Производители, застигнутые мировым кризисом, снижали свои затраты по всем направлениям, что и послужило причиной ряда громких провалов 2008-2009 гг. Об одном из них речь пойдет в продолжении этого материала, которое выйдет в ближайшее время.
Сохранность наших файлов и данных напрямую зависит от состояния жесткого диска, на котором они хранятся. Важно иметь полное представление о работе этого устройства и вовремя спрогнозировать возможные сбои. Это даст возможность перенести важную информацию на резервный носитель. Полное представление о том, в каком состоянии механическая часть жесткого диска, поверхность физических дисков даёт технология S.M.A.R.T.
Сокращение S.M.A.R.T. обозначает в свободном переводе технология самоконтроля, анализа и отчета. Соответственно названию она занимается самоконтролем диска, анализом параметров на предмет предполагаемого сбоя и отчета по набору атрибутов.
Одна группа атрибутов отражает состояние диска в данный момент, другая фиксирует механический износ деталей устройства. У каждого атрибута есть свой номер и значение(Value ). Диск хранит значение атрибута в удобном для себя шестнадцатеричном формате (Raw value ), а программа пересчитывает его в понятные нам десятичные цифры. Современная система информационной безопасности позволяет обеспечить такие параметры диска, при которых злоумышленник не сможет получить доступ к конфиденциальной информации.
Система DLP создает защитный цифровой барьер, который и препятствует утечкам информации. Для оценки состояния есть пороговые значения атрибутов (Threshold ), их определяет производитель диска. Значение ниже порога, уже не нормальная работа жесткого диска или вообще неисправность. Очень полезное для прогноза сбоев, наихудшее значение атрибута (Worst ),показывает худшее число, которое принимал параметр за весь период работы диска. Дополнительно многие программы показывают значение атрибута в цвете (зеленый, желтый, красный) или шкалой. Value обычно имеет диапазон от 0 до 100 , но есть атрибуты со значениями выше 200.
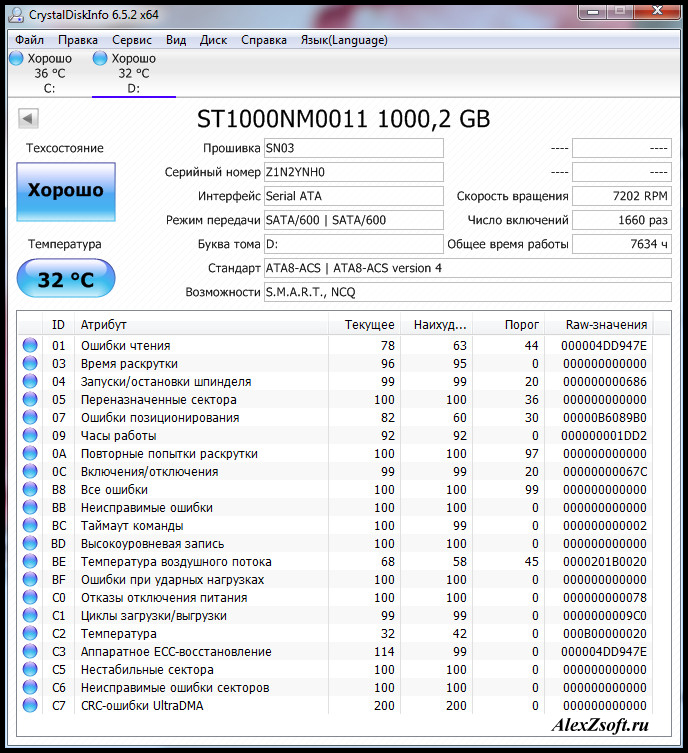
Атрибутов S.M.A.R.T. достаточно много, рассмотрим основные и жизненно важные. Набор параметров возьмем из статьи о программе для проверки жесткого диска. Как выглядит таблица S.M.A.R.T. показано на картинке ниже.
Здесь есть номер атрибута, его описание, значение Value , значение Worst , Raw value в hex формате и пороговое значение Threshold . Рядом с атрибутом кружок, по цвету которого можно оценить значение атрибута.
001 Raw Read Error Rate
— Как часто появляются ошибки чтения из-за аппаратной части накопителя. Ошибок нужно бы поменьше.
003 Spin Up Time
– Как быстро диск набирает рабочую скорость. С износом повышается.
004 Start/Stop Count
– Количество запусков и остановок диска. Не критично.
005 Reallocation Sector Count
– Важный атрибут. Количество переназначения нечитаемых (Bad ) секторов в резервную область диска.
Сбойный сектор заменяется запасным из резервной области.
При попадании на Bed головка уходит на переназначенный сектор, считывает информацию и возвращается. Операция переназначения называется Remap . Большое количество переназначенных секторов говорит о дефекте поверхности диска и возможно скорой потери данных.
007 Seek Error Rate
– Ошибки позиционирования магнитных головок диска. Вызываются износом механики или поверхности.
008 Seek time Performance
– Как быстро позиционируются головки.
Повышается с износом.
009 Power-On Hours Count
– Время работы диска. В качестве Threshold
время наработки
на отказ при тестах производителя.
010 Spin Retry Count
– Счетчик числа повторной попытки раскрутить диск до рабочей скорости. Если таких попыток становиться много, скорый отказ неизбежен.
011 Recalibration Retries
– Счетчик повтора рекалибровки при неудачной первой попытке. Показывает износ механики.
012 Device Power Cycle Count
– Сколько раз включился-выключился диск. Чистая статистика использования.
013 Soft read error rate
– Число программных ошибок при чтении. К механике не имеет отношения и не критичен.
183 SATA Downshift Error Count
– Присутствует у дисков производства Samsung и Western Digital. Информационный параметр, не критичен, но указывает на старение диска.
184 End To End Error Count
– Диск проверяет и сравнивает данные, которые переданы и которые приняты материнской платой. Атрибут выводит количество ошибок сравнения. Не критичен.
187 Reported Uncorrectable Error
– Не восстановимые ошибки. Чем меньше ошибок, тем лучше. Значение ухудшается при износе.
188 Reported Command Timeouts
– Рапорт о задержке команды. Не критичен.
190 Airflow Temperature
– Температура внутри корпуса жесткого диска. Указаны минимальное и максимальное значения.
194 HDA Temperature
– Показания термодатчика внутри корпуса диска, используются для расчета атрибута 190.
195 Hardware ECC Recovered
– Сколько производилось коррекций ошибок аппаратной частью диска. Повышение числа предупреждает о возможном отказе.
196 Reallocation Event Count
– Еще один важный атрибут. Считает удачные и неудачные попытки Remap
. Показание растет
даже после полного использования резервной области диска. Критичен.
197 Current Pending Errors Count
– Число секторов диска операции, с которыми выдают ошибки. Программа готовит их для возможного переназначения (Remap ). Рост количества секторов сигнализирует о возможном сбое и потере информации.
198 Uncorrectable Errors Count
– Число ошибок обращения к сектору, которые нельзя исправить. Это критично.
199 UltraDMA CRC Errors
– Ошибки контрольной суммы при передаче данных. Говорит скорее о неисправном шлейфе или окисленных контактах разъёма, чем о неисправном диске.
200 Write Error Rate
— Количество ошибок записи на диск. Увеличивается со сроком эксплуатации.
201 Soft Read Error Rate
– Как часто появляются программные ошибки чтения информации. Не критично.
Из описанных параметров можно получить полное представление о состоянии поверхности диска и ресурсе механики.
Если какой либо из критичных параметров достиг значения Threshold
нужно немедленно делать резервную копию информации. При сбоях по критичным атрибутам восстановление утраченных данных крайне затруднено или часто вообще невозможно.
Привет всем! В прошлой статье мы рассмотрели . А сегодня мы рассмотрим как посмотреть здоровье жесткого диска, например для того, чтобы знать что с ним в ближайшее время ничего не случится. Ну или случилось и вы ещё успеваете сохранить данные.
Для начала скачиваем бесплатную программу:
Запускаем и:

- Выбираем диск, здоровье которого вы хотите проверить
- Далее нажимаем на лупу
- И жмем SMART

В ячейке Attribute Name название smart теста. Более подробную информацию вы можете узнать в файле, нажав на кнопку скачать. Это информация с википедии. Так же в файле будет указаны критические названия и несущественные. Если у вас критические наименования превысили норму, то задумайтесь о смене жесткого диска.
Она русская и менее функциональная.
Так же и обращаем внимание на температуру. Я вот делал эксперимент по этому поводу, ssd стоит у меня на боковой стенке (у корпуса zalman есть специальное крепление), а второй жесткий диск на своем месте, да ещё и впереди стоит кулер, который дополнительно его охлаждает. Так вот, с кулером и без, разница в 4 градуса. Так что я буду ssd переставлять ближе к кулеру. Ведь когда выходит жесткий диск из строя, первая причина это температура.
Критические значения
Особое внимание уделите следующим параметрам:
- 01 (01) Raw Read Error Rate (ошибки чтения) - на сколько часто появляются ошибки при чтении с диска данных.
- 03 (03) Spin-Up Time (время раскрутки) - на сколько быстро раскрутится пластина из состояния покоя, до рабочего состояния.
- 05 (05) Reallocated Sectors Count (переназначенные сектора) - количество переназначенных секторов. Если количество переназначенных секторов закончится, то появятся .
- 07 (07) Seek Error Rate (ошибки позиционирования) - если головка становится не точно на дорожку, это свидетельствует о повреждении механики. Причиной этого может быть перегрев. Чем чаще головка не попадает на дорожку, тем выше значение.
- 10 (0A) Spin-Up Retry Count (повторные попытки раскрутки) - так же при неисправности механики. Ошибка появляется, когда диск не может раскрутится до рабочей скорости.
- 196 (C4) Reallocation Event Count (события переназначения) - на сколько много производилось переназначение битых секторов на резервные.
- 197 (C5) Current Pending Sector Count (нестабильные сектора) - на сколько много секторов претендентов на переназначения. Эти сектора ещё не являются битыми, но у них слабый отклик.
- 198 (C6) Uncorrectable Sector Count (неисправные ошибки секторов) - из-за поврежденной механики, показывает количество неудачных раз чтения секторов.
- 220 (DC) Disk Shift (сдвиг диска) - из-за удара, пластины могут быть сбиты с оси.
На этом все. Не критические ошибки и описание вы найдете скачав в документе выше. Вот таким образом можно проверить здоровье жесткого диска с помощью этих 2х программ. А какой пользоваться, вам решать.
Маленький рассказ об S.M.A.R.T. атрибутах, их важности и понимании. В статье пойдет речь об расшифровке всех smart атрибутов ATA дисков. В предыдущих статьях речь шла об и . Теперь хочу немного описать атрибуты обычных АТА дисков на примере Seagate Barracuda ES.2 (ST31000340NS). Так же определим самые важные атрибуты, на которые нужно обращать внимание при мониторинге дисков используя smartctl. Для начала, можно убедиться, что наш диск поддерживает смарт
[email protected] s01:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Model Family: Seagate Barracuda ES.2 Device Model: ST31000340NS Serial Number: 9QJ2ADVC … ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Fri Feb 21 16:18:35 2014 CET … SMART support is: Available - device has SMART capability. SMART support is: Enabled
Две последние строки свидетельствуют о том, что диск поддерживает smart и можно посмотреть значение всех его атрибутов и их интерпретация будет корректной(интерпретация RAW_VALUE) . В данном случаи тип интерфейса (устройства) не указывался явно (не было указанно атрибут «-d»), по этому smartctl автоматически определил тип устройства и сказал, что «SMART support is: Enabled». Но если используются, к примеру массивы дисков (RAID контроллер), то smartctl может сказать, что смарт не поддерживается:
[email protected]:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SMC Product: SMC2108 Revision: 2.90 User Capacity: 2,996,997,980,160 bytes Logical block size: 512 bytes Logical Unit id: 0xSerial number: Device type: disk Local Time is: Fri Feb 21 17:32:27 2014 IST Device does not support SMART
Но на самом деле, нужно просто знать (или подбирать) какие дисковые массивы используются, и тогда можно получить желаемый результат явно указав тип устройства:
[email protected]:~# smartctl -d megaraid,14 -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SEAGATE Product: ST1000NM0001 Revision: 0002 User Capacity: 1,000,204,886,016 bytes Logical block size: 512 bytes Logical Unit id: 0x5000c50041080343 Serial number: Z1N0TV980000C2157TYR Device type: disk Transport protocol: SAS Local Time is: Fri Feb 21 17:34:45 2014 IST Device supports SMART and is Enabled Temperature Warning Enabled
Также может быть проблема в версии smartctl ибо не все жесткие диски добавляются в базу SMART сразу после выхода в мир нового HDD или RAID контроллера. Или же в BIOS отключено поддержку (нужно включить). Так же может быть проблема в прошивке (firmware) самого жесткого диска. Можете также стоит для начала попытаться включить SMART командой:
[email protected]:~# smartctl -s on /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF ENABLE/DISABLE COMMANDS SECTION === SMART Enabled.
Следующая, интересующая нас часть вывода покажет суммарный результат проверки статуса здоровья диска (Если не Passed – нужно проводить замену диска). Так же выводится дополнительные характеристики диска и предполагаемое время выполнения коротких и длинных тестов.
[email protected]:~# smartctl -Hc /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (41) The self-test routine was interrupted by the host with a hard or soft reset. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (226) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x003d) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported.
В нашем случаи тип устройства определился автоматически и теперь можно вывести самое интересное — список атрибутов.
[email protected]:~# smartctl -A /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 068 059 044 Pre-fail Always - 130449727 3 Spin_Up_Time 0x0003 099 099 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 23 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 4 7 Seek_Error_Rate 0x000f 063 039 030 Pre-fail Always - 549998464474 9 Power_On_Hours 0x0032 052 052 000 Old_age Always - 42335 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 037 020 Old_age Always - 63 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 093 000 Old_age Always - 4295032870 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 076 049 045 Old_age Always - 24 (Min/Max 18/26) 194 Temperature_Celsius 0x0022 024 051 000 Old_age Always - 24 (0 17 0 0) 195 Hardware_ECC_Recovered 0x001a 041 021 000 Old_age Always - 130449727 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
Используя SMART можно предугадать с довольно большой вероятностью проблемы связанные с:
- Магнитными головками диска
- Физическими повреждениями диска
- Логическими ошибками
- Механическими проблемами (проблемы привода, системы позиционирования)
- Подачей питания (платы)
- Температурой
Расшифруем полученный вывод.

Каждый атрибут имеет группу значений:
- ID# — идентификационный номер атрибуты (детали ). Каждый атрибуты имеет свой уникальный ID, который должен быть одинаковым для всех фирм производителей дисков.
- ATTRIBUTE_NAME – название атрибута. Так как разные фирмы производители дисков могут называть атрибуты по своему (сокращать, синонимы), лучше всего ориентироваться по ID атрибута.
- FLAG (Status flag) – каждый атрибут имеет определенный флаг, назначенный фирмой разработчиком диска. В ОС с графическим интерфейсом значения этого флага предоставляется в виде набора буквенных обозначений – w,p,r,c,o,s (расшифровка ниже). И эти наборы предоставляются в виде шестнадцатеричного числа которые вы видели выше.
- W arranty: Указывает на жизненно важный атрибут диска и покрывается гарантией. Если этот флаг установлен и значение атрибута с этим флагом достигнет порогового (threshold) значения, в то время, когда диск еще на гарантии, то фирма должна будет заменить диск бесплатно.
- P erformance: Указывает на атрибут, который представляет показатель производительности диска – не критический.
- Error R ate: Атрибут с частотой ошибок.
- C ount of occurrences: Атрибут-счетчик происшествий.
- O nline test: Атрибут, который обновляет значения только через on-line тесты. Если не указан, то обновляется через off-line тесты.
- S elf preserving: Указывает на атрибут который может собирать и сохранять данные о диска, даже если S.M.A.R.T. отключен.
- Value – Текущее значение атрибута(оценка атрибута диска на основе Raw_value). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Это значение атрибута нужно сравнивать с пороговым (threshold) значением. Если это критический атрибут и значение ниже порогового — нужно проводить замену диска.
- Worst – Самое низкое значение атрибута за жизненный цикл диска. Значение может изменяться на протяжении жизни диска, и не должно быть ниже или равным пороговому значению (threshold).
- Thresh (Threshold) – Пороговое значения атрибута назначенное создателем диска. Значение не меняется за жизненный цикл диска. Если значение Value атрибута станет равным или меньше порогового – появиться уведомление в колонке WHEN_FAILED. И диск нужно заменить.
- Type – тип атрибута. Может быть критическим (pre-fail), который указывает на предстоящий отказ диска из-за ошибок или не критический, указывающий на достижение конца жизненного цикла диска.
- Raw_value – Объективное значения атрибута, которое показывается в десятичном формате (вычисляется firmware диска) и известных только производителю единицах (имеет связь с Value, Threshold и Worst значениями).
- WHEN_FAILED – Указывает на проблемы с атрибутом.
Атрибут диска примет значение failed, в случаи:
Value = f(Raw_value ) <= Threshold
- f(Raw_value) – функция вычисления деградации (уменьшения) значения параметра Value в зависимости от значения Raw_value.
Недостатки такого подхода к вычислению деградации диска:
- Для каждого производителя дисков и даже модели диска функция f(Raw_value) вычисляется по-разному.
- Оценка каждого атрибута подсчитывается независимо друг от друга – т.е. игнорируются связи между атрибутами.
Теперь хочу представить таблицу с перечисленными всех атрибутов. Те атрибуты, которые выделены розовым — относятся к атрибутам критическим. К тому же, указано тип параметра в зависимости от величины значения. Т.е. чем больше значение параметра, тем лучше состояние здоровья диска или наоборот.
Теперь приступим к атрибутам:
| #ID | HEX | Имя атрибута | Лучше если… | Описание |
|---|---|---|---|---|
| 01 | 01 | Raw Read Error Rate | Частота ошибок при чтении данных с жёсткого диска. Происхождение их обусловлено аппаратной частью винчестера. | |
| 02 | 02 | Throughput Performance | Общая производительность накопителя. Если значение атрибута уменьшается перманентно, то велика вероятность проблем с винчестером. | |
| 03 | 03 | Spin-Up Time | Время раскрутки шпинделя из состояния покоя (0 rpm) до рабочей скорости. В поле Raw_value содержится время в миллисекундах/секундах в зависимости от производителя | |
| 04 | 04 | Start/Stop Count | * | Полное число запусков, остановок шпинделя. Иногда в том числе количество включений режима энергосбережения. В поле raw value хранится общее количество запусков/остановок жёсткого диска. |
| 05 | 05 | Reallocated Sectors Count | Число операций переназначения секторов. При обнаружении повреждённого сектора на винчестере, информация из него помечается и переносится в специально отведённую зону, происходит утилизация bad блоков, с последующим консервированием этих мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated Sectors Count, тем хуже состояние поверхности дисков - физический износ поверхности. Поле raw value содержит общее количество переназначенных секторов. | |
| 07 | 07 | Seek Error Rate | Частота ошибок при позиционировании блока магнитных головок. Чем больше значение, тем хуже состояние механики, или поверхности жёсткого диска. | |
| 08 | 08 | Seek Time Performance | Средняя производительность операции позиционирования. Если значение атрибута уменьшается, то велика вероятность проблем с механической частью. | |
| 09 | 09 | Power-On Hours (POH) | Время, проведённое устройством, во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ. | |
| 10 | 0A | Spin-Up Retry Count | Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. | |
| 11 | 0B | Recalibration Retries | Количество повторов рекалибровки в случае, если первая попытка была неудачной. | |
| 12 | 0C | Device Power Cycle Count | Число циклов включения-выключения винчестера. | |
| 13 | 0D | Soft Read Error Rate | Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. | |
| 187 | BB | Reported UNC Errors | Неустранимые аппаратные ошибки. | |
| 190 | BE | Airflow Temperature | Температура воздуха внутри корпуса жёсткого диска. Целое значение, либо значение по формуле 100 - Airflow Temperature | |
| 191 | BF | G-sense error rate | Количество ошибок, возникающих в результате ударов. | |
| 192 | C0 | Power-off retract count | Число циклов аварийных выключений. | |
| 193 | C1 | Load/Unload Cycle | Количество циклов перемещения блока головок в парковочную зону. | |
| 194 | C2 | HDA temperature | Показания встроенного термодатчика накопителя. | |
| 195 | C3 | Hardware ECC Recovered | Число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по внешнему интерфейсу). | |
| 196 | C4 | Reallocation Event Count | Число операций переназначения в резервную область, успешные и неудавшиеся попытки. | |
| 197 | C5 | Current Pending Sector Count | Число секторов- кандидатов на перенос в резервную зону. Помечены как не надёжные. При последующих корректных операциях атрибут может быть снят. | |
| 198 | C6 | Uncorrectable Sector Count | Число некорректируемых ошибок при обращении к сектору. | |
| 199 | C7 | UltraDMA CRC Error Count | Число ошибок при передаче данных по внешнему интерфейсу. | |
| 200 | C8 | Write Error Rate / Multi-Zone Error Rate | Общее количество ошибок при заполнения сектора информацией. Показатель качества накопителя. | |
| 201 | C9 | Soft read error rate | Частота появления «программных» ошибок при чтении данных с диска, а не аппаратной части HDD. | |
| 202 | Ca | Data Address Mark errors | Число ошибок адресно помеченной информации (Data Address Mark (DAM)).Если автоматически не корректируется - заменить устройство. | |
| 203 | CB | Run out cancel | Количество ошибок ECC данных, присоединяемые к передаваемому сигналу, позволяющие принимающей стороне определить факт сбоя или исправить несущественную ошибку. | |
| 204 | CC | Soft ECC correction | Количество ошибок ECC, скорректированных программным способом. | |
| 205 | CD | Thermal asperity rate (TAR) | Число ошибок в следствии температурных колебаний. | |
| 206 | CE | Flying height | * | Высота между головкой и поверхностью диска компьютера. |
| 209 | D1 | Offline seek performance | * | Drive’s seek performance during offline operations. |
| 220 | DC | Disk Shift | Дистанция смещения блока дисков относительно шпинделя. В основном возникает из-за удара или падения. | |
| 221 | DD | G-Sense Error Rate | Число ошибок, возникших из-за внешних нагрузок и ударов. Атрибут хранит показания встроенного crash датчика. | |
| 222 | DE | Loaded Hours | * | Время, проведённое блоком магнитных головок между выгрузкой из парковочной области в рабочую область диска и загрузкой блока обратно в парковочную область. |
| 223 | DF | Load/Unload Retry Count | * | Количество новых попыток выгрузок/загрузок блока магнитных головок винчестера в/из парковочной области после неудачной попытки. |
| 224 | E0 | Load Friction | Величина силы трения блока магнитных головок при его выгрузке из парковочной области. | |
| 225 | E1 | Load Cycle Count | Число циклов вход-выход в парковочную зону. | |
| 226 | E2 | Load ‘In’-time | * | Время, за которое привод выгружает магнитные головки из парковочной области на рабочую поверхность диска. |
| 227 | E3 | Torque Amplification Count | Количество попыток скомпенсировать вращающий момент. | |
| 228 | E4 | Power-Off Retract Cycle | Количество повторов автоматической парковки блока магнитных головок в результате выключения питания. | |
| 230 | E6 | GMR Head Amplitude | * | Амплитуда «дрожания» (расстояние повторяющегося перемещения блока магнитных головок). |
| 231 | E7 | Temperature | Температура жёсткого диска. | |
| 240 | F0 | Head flying hours | * | Время позиционирования головки. |
| 250 | FA | Read error retry rate | Число ошибок во время чтения жёсткого диска. |
Атрибуты дисков нужно смотреть в целом и самостоятельно прогнозировать замену, не только опираясь на smart атрибуты. Нужно дополнительно проводить тесты на бедблоки и запускать fscheck и smart тесты, о которых пойдет речь в следующих статьях.
Рекомендуем также
 Виды смайликов и их значение
Виды смайликов и их значение
 Настройка подключения в Putty и WinSCP Winscp перенос настроек
Настройка подключения в Putty и WinSCP Winscp перенос настроек
 Be-on-Road – бесплатный оффлайн GPS навигатор Карты для be on road 3
Be-on-Road – бесплатный оффлайн GPS навигатор Карты для be on road 3
 Как самому изменить имя в ВК: подробная инструкция для смены
Как самому изменить имя в ВК: подробная инструкция для смены
 Steam client not found — что делать и как исправить сбой Что за ошибка steam client not found
Steam client not found — что делать и как исправить сбой Что за ошибка steam client not found
 Acrobat reader редактирование pdf
Acrobat reader редактирование pdf