Ваше имя url http xa. УРЛ со слешем или без - почему правильно именно так? Письма от «государственных организаций»
Споры по этому вопросу - как правильно писать URL, со слешем на конце или без? - были и будут. Аргументация встречается разнообразная, и часто противоречива. А расплату за неверную запись универсального локатора ресурса (URL) воображают двух видов. Со стороны поисковиков - это якобы штрафные санкции за дубли страниц. С точки зрения производительности - якобы лишний редирект на страницу верной записи, автоматически генерируемый сервером.
Однако, разбирая технические спецификации стандартов Интернета, в частности документ " RFC 1738 - Uniform Resource Locators (URL)", приходится признать, что оба варианта записи адреса веб-ресурса формально правильные, и санкция за использование того или иного варианта - не более чем бзик поисковой системы или байки псевдо-SEO-шников.
С позиции лаконичности, более правильным представляется вариант без слеша на конце вне зависимости от того, адресует ли ваша ссылка "файл" на сервере или "папку", косвенное доказательство чему будет продемонстрировано ниже. Но и нет ни одного утверждения в документе, что иной вариант неверный или ссылается совсем на другой ресурс.
Загружать вас многостраничным переводом упомянутого RFC не стану, так как, во-первых, целью вопроса были слеши на конце URL, и во-вторых, публикация адресована простым пользователям движков, в том числе и , которым вся детализация не интересна, они ждут кратких разъяснений и доказательств по существу. Соответственно, я буду цитировать выдержки из сего документа в качестве доказательной базы и пояснять. Кому и это не интересно, может сразу смотреть вывод в конце статьи.
Общий синтаксис URL
Первым делом привлеку внимание к выдержке из параграфа 2. General URL Syntax (общий синтаксис URL). В каждом случае буду приводить фрагмент текста на языке оригинала и следом перевод на русский язык.
URLs are used to `locate" resources, by providing an abstract identification of the resource location. URLы используются для "нахождения" ресурсов, предоставляя абстрактное обозначение местоположения ресурса.
То есть сам URL - это чистая абстракция. Что он может показаться нам внешне похожим на имя файла или папки, вовсе не означает физическое указание на именно такой-то файл, а не какой-нибудь другой в файловом пространстве сервера. Ниже в документе об этом будет заявлено прямо.
Заметка Вообще в отношении http-ссылок в принципе неверно говорить, что например
- http://domain.com/path/subpath/filename.txt - якобы указывает на файл
- http://domain.com/path/subpath/ - якобы указывает на папку
- http://domain.com/path - якобы неверно указывает на папку
Мы просто привыкли так говорить, потому что удобно ассоциировать ссылки с файлами на сайте. В действительности все эти ссылки указывают на некие ресурсы, никоим образом не обозначая тип ресурса. Что же скрывается за каждым ресурсом, то есть какой именно реальный файл или папка и какой тип контента будет отдан по такой ссылке, то уже определено конфигурацией сервера.
Важно уяснить, что в ссылках нет такого понятия как "файл", "папка", "подпапка", "текст", "картинка", "html", "скрипт", "таблица стилей" и так далее. Никакой слеш на конце или его отсутствие не значит ровным счётом ничего до тех пор, пока ссылка не пройдёт трансформацию внутри сервера, и уже он сам решит, куда же на самом деле указывает ссылка и какой контент какого типа скрывается за ней. Только это решение относится к внутренней архитектуре сервера.
Иерархические схемы
Далее выдержка из параграфа 2.3 Hierarchical schemes and relative links (иерархические схемы и относительные ссылки).
Some URL schemes (such as the ftp, http, and file schemes) contain names that can be considered hierarchical; the components of the hierarchy are separated by "/". Некоторые схемы URL (такие как ftp, http и file) содержат имена, которые можно считать иерархическими; элементы иерархии разделены символом "/".
То есть утверждается, что в отдельных схемах адресов содержимое локатора ресурса не воспрещено подразумевать иерархическим, причём пока не оговаривалось, что иерархия эквивалентна какой-либо форме, скажем файловой.
Общий синтаксис сетевой схемы
Далее выдержка из параграфа 3.1. Common Internet Scheme Syntax (общий синтаксис сетевой схемы).
//
Заметка Это, кстати, ответ на вопрос, производный от рассматриваемого нами. Нередко и по такому вопросу спорят: как правильно давать ссылку на домен (хост) - без слеша в конце или со слешем?
Как правильно http://domain.com/ или http://domain.com ?
И так и так правильно. Просто первый слеш после имени хоста предназначен для отделения имени пути от имени хоста. Тот же параграф документа сообщает об этом так:
Url-path The rest of the locator consists of data specific to the scheme, and is known as the "url-path". It supplies the details of how the specified resource can be accessed. Note that the "/" between the host (or port) and the url-path is NOT part of the url-path. Остальная часть локатора состоит из данных, характерных для схемы, и известна как "url-path" (путь URL). Она сообщает подробности, как можно получить доступ к указанному ресурсу. Обратите внимание, что символ "/" между хостом (или портом) и путём URL - это не часть url-path.
Ни словом не обязали вас ставить этот замыкающий символ или не ставить, когда url-path равен пустой строке (как сказали бы многие из нас, когда URL ссылается в корень сайта). Никто не имеет права применить к вам штрафные санкции "за два дубля главной страницы", ибо согласно спецификации, в обоих случаях вы ссылаете URL на один и тот же ресурс.
Продолжим ещё одной выдержкой из того же параграфа.
The url-path syntax depends on the scheme being used, as does the manner in which it is interpreted. Синтаксис url-path зависит от используемой схемы, как и способ, которым он интерпретируется.
Это лишнее подтверждение, что у каждой схемы локатора своё понятие "иерархии" и способ её интерпретации.
Иерархия
For some file systems, the "/" used to denote the hierarchical structure of the URL corresponds to the delimiter used to construct a file name hierarchy, and thus, the filename will look similar to the URL path. This does NOT mean that the URL is a Unix filename. Символ "/" использован для обозначения иерархической структуры URL соответственно разделителю, используемому в конструировании иерархии файловых имён, и таким образом в некоторых файловых системах имя файла выглядит подобным пути URL. Но это не означает, что URL - это Unix-подобное имя файла.Несмотря на то, что этот параграф относится к схеме ftp, тем не менее его утверждения распространимы и на другие схемы (http, gopher, prospero и так далее). Лишь в схеме file символ слеша логично обозначает то же, что и в именах файлов, например file://server_or_device/path/subpath/filename.txt .
Http
An HTTP URL takes the form:
http://
Заметка Здесь также утверждается, что можно указывать ссылку без оконечного слеша. В данном случае речь шла о ситуации, когда путь ссылки пустой - указывает на корень хоста.
Формальная запись
И наконец выдержка из параграфа 5. BNF for specific URL schemes (формальная запись для конкретных схем URL).
Здесь в квадратных скобках указаны опциональные части. Звёздочка перед скобкой обозначает 0 или более повторов такого фрагмента, как указан в скобках. Вертикальную черту следует понимать как ИЛИ.
Hostport = host [ ":" port ] ... ... httpurl = "http://" hostport [ "/" hpath [ "?" search ]] hpath = hsegment *[ "/" hsegment ] hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ] search = *[ uchar | ";" | ":" | "@" | "&" | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "I" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" | "S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z" alpha = lowalpha | hialpha digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" safe = "$" | "-" | "_" | "." | "+" extra = "!" | "*" | """ | "(" | ")" | "," hex = digit | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" escape = "%" hex hex unreserved = alpha | digit | safe | extra uchar = unreserved | escape
Обратите внимание, как точно по правилам формируется элемент hpath - путь ссылки. Элементы hsegment пути - сегменты - разделяются слешем. Словно намекая на важную идею, что слеш делит путь на иерархические части и всегда находится внутри. В принципе не исключается, что последний элемент hsegment может являться пустой строкой (это следует из его определения), и тогда на конце URL невольно появляется закрывающий слеш.
Вывод
Деление пути на сегменты с помощью символа слеша подразумевает наличие непустых имён этих сегментов. Соответственно, ссылка со слешем на конце видится нелогичной (хотя и не воспрещена) в том смысле, что она вроде бы указывает на некий последний сегмент пути, но притом никак не называет этот сегмент. Точно так как нелогична (но тоже не воспрещена) ссылка http://domain.com/level1////levelX , не называющая промежуточные сегменты пути, если путь рассматривать не как набор параметров, а как иерархическую структуру.
Просторечным языком смысловое наполнение двух ссылок можно пояснить так:
- - адресует в дефолтную начальную точку второго уровня иерархии
- - адресует в неопределённую точку внутри второго уровня иерархии, то есть как бы на сервер возлагают задачу, что "мы обращаемся ко второму уровню иерархии, а ты сам определи, какую точку считаешь в этом уровне дефолтной начальной".
Из всего сказанного выше следует , что аналогично тому, как ссылки
- http://domain.com
- http://domain.com/
адресуют посетителя в корень сайта, так и например ссылки
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
адресуют посетителя во второй уровень иерархии ресурса. А то что некий сервер может интерпретировать слеш на конце по-своему и начать внутренне редиректить на дефолтную начальную точку уровня - скажем на файл index.html , это уже частный случай конкретной конфигурации. Точно так как и в реализации системы человеко-понятных URL все записи редиректов с помощью серверного модуля mod_rewrite определяют своё (присущее конкретному движку) понятие иерархического строения URL, в котором элементы пути могут приравниваться к параметрам запроса и вовсе не иметь общего с файловой структурой сайта (классический пример: http://domain.com/ru/path , элемент ru - это параметр текущего языка, а не папка на сайте).
Особо подчеркну, что это внутренние знания сервера, обусловленные его конфигурацией, а также установленным на сайте движком. Внешний сервис, скажем тот же поисковик, домыслов делать не может и понятия не имеет, отличаются ли и чем ссылки со слешем и без, если только сервер сайта специально не настроили так, чтобы по таким ссылкам выдавать разный контент.
К сведению
На уровне реализации вопрос слешей на концах не имеет принципиального значения, чему множество подтверждений среди именитых порталов. На одних все ссылки завершают слешем, на других - без слеша. Главное чтобы контент по ссылкам не оказывался разным, и ещё для Яндекса нужно прописать 301-й редирект с тех ссылок, которыми вы не пользуетесь (скажем оканчивающихся слешем), на те, которыми пользуетесь. Дело в том, что по неподтверждённым утверждениям службы поддержки Яндекса, этот поисковик якобы может ошибаться и не "склеивать" (запоминать в своих знаниях) или с некоторым запозданием склеивать слеш-без-слешевые адреса в один.

Вот пример реализации такого редиректа с помощью корневого файла .htaccess :
# если входной url оканчивается слеш(ем, ами), # задаём 301-й редирект на страницу без слеша RewriteCond %{REQUEST_URI} ^/.+/$ RewriteRule ^(.*?)/+$ http://%{HTTP_HOST}/$1
Гуглу (опять же по сведениям , не подтверждённым экспериментом) эти редиректы не важны, так как он будто бы умеет склеивать такие адреса правильно и без редиректов.
Помните Есть немало людей, считающих себя SEO-специалистами. Но не каждый из них таким является. Более того, темой SEO часто спекулируют без должных знаний и оснований, просто в расчёте на то, что и вы неосведомлены в этой области, поэтому легко поверите в любую "лапшу". Когда вам говорят, что какая-то ваша страница "вылетела из индекса", воспользуйтесь очень хорошей рекомендацией Яндекса: Узнавать об ошибках индексирования , если таковые возникают, можно в сервисе Яндекс.Вебмастер. В этом сервисе всегда можно увидеть список ваших страниц, находящихся в поиске и список страниц, по какой-то причине исключённых из поиска . Похожий сервис есть и у Гугла. Доверяйте этим знаниям, а не мнению псевдо-специалистов, которые где-то что-то краем уха слышали, и на том основании рекомендуют вам делать так, как им кажется единственно правильным.
Вот Очень интересная публикация Малоизвестные факты SEO , вышедшая в апреле 2017 года. Там представлено большое исследование со множеством скриншотов, которое начиналось с целью проверить справедливость нескольких популярных суждений в области поискового продвижения и на понятных примерах донести результаты до обычного владельца сайта. То же исследование попутно демонстрирует молодому читателю ряд очевидных, обыденных, и скорее даже неприметных, но всё же удивительных особенностей органической выдачи в поисках Google и Yandex.
Вот Хотя следующая ссылка почти не касается SEO, всё же станет привлекательной для seo-мастеров, находящихся сейчас в поиске дополнительных заказов. Под ссылкой размещено коммерческое предложение, ребята нашли любопытный способ использования сайта. Частному бизнесу предлагают создание рекламного щита онлайн на основе какой-то специальной темы, под управлением которой сайт, а точнее его первый экран выглядит словно бы баннерная растяжка на билбордах наружной рекламы. На смартфоне повернул экран, растяжка стала вертикальной и занимает всю площадь экрана, повернул назад, стала горизонтальной и снова на весь экран. А под первым экраном есть текстовый придаток, куда пользователи обычно не скролят, но поисковик хорошо видит этот текст. Так вот самые шустрые буратины регионального бизнеса покупают себе эти недорогие онлайн билборды в качестве выгодной альтернативы контекстной рекламе и контекстно-медийной сети Яндекса и Гугла. А чтобы по-максимуму тусоваться в местном поисковом индексе, на продвижение своего щита готовы стегнуть денег сразу на кучу seo-текстов, что пахнет некислой суммой. Судя по слухам, заказы на 30 килорублей проскакивают, и так как ребята аутсорсят их партнёрам сеошникам, тут можно навести мосты партнёрства и получать хороший приработок.
По разным данным от 50 до 95% всех электронных писем в мире - спам от кибермошенников. Цели рассылки таких писем просты: заразить компьютер получателя вирусом, украсть пароли пользователя, заставить человека перевести деньги «на благотворительность», ввести данные своей банковской карты или прислать сканы документов.
Часто спам напрягает с первого взгляда: кривая верстка, автоматически переведенный текст, формы для ввода пароля прямо в теме письма. Но бывают вредоносные письма, которые прилично выглядят, тонко играют на эмоциях человека и не вызывают сомнений в их правдивости.
В статья будет рассказано о 4 типах мошеннических писем, на которые чаще всего ведутся россияне.
1. Письма от «государственных организаций»



Мошенники могут прикидываться налоговой, Пенсионным фондом, Роспотребнадзором, санэпидемстанцией и другими госорганизациями. Для убедительности в письмо вставляют водяные знаки, сканы печатей и государственную символику. Чаще всего задача преступников - напугать человека и убедить его открыть файл с вирусом во вложении.
Обычно это шифровальщик или блокатор винды, который выводит компьютер из строя и требует прислать платное SMS для возобновления работы. Вредоносный файл может маскироваться под судебное постановление или повестку о вызове к начальнику организации.
Страх и любопытство отключают сознание пользователя. На форумах бухгалтеров описаны случаи, когда сотрудницы организаций приносили файлы с вирусами на свои домашние компьютеры, так как не могли открыть их в офисе из=за антивируса.
Иногда мошенники просят отправить в ответ на письмо документы, чтобы собрать сведения о фирме, которые пригодятся для других схем обмана. В прошлом году одна группа мошенников смогла обмануть множество людей, использовав прием отвлечения внимания «просьба отправить бумаги по факсу».
Когда бухгалтер или менеджер читал это, он сразу проклинал налоговую «Вот мамонты там сидят, е-мое!» и переключал свои мысли с самого письма на решение технических проблем с отправкой.
2. Письма от «банков»


Блокаторы винды и шифровальщики могут прятаться в фальшивых письмах не только от госорганизаций, но и от банков. Сообщения «На Ваше имя взяли кредит, ознакомьтесь с судебным иском» действительно могут напугать и вызвать огромное желание открыть файл.
Также человека могут убедить войти в фальшивый личный кабинет, предлагая посмотреть начисленные бонусы или получить приз, который он выиграл в «Лотерее Сбербанка».
Реже мошенники отправляют счета для оплаты сервисных сборов и дополнительных процентов по кредиту, на 50-200 рублей, которые проще заплатить, чем разбираться.
3. Письма от «коллег»/«партнеров»
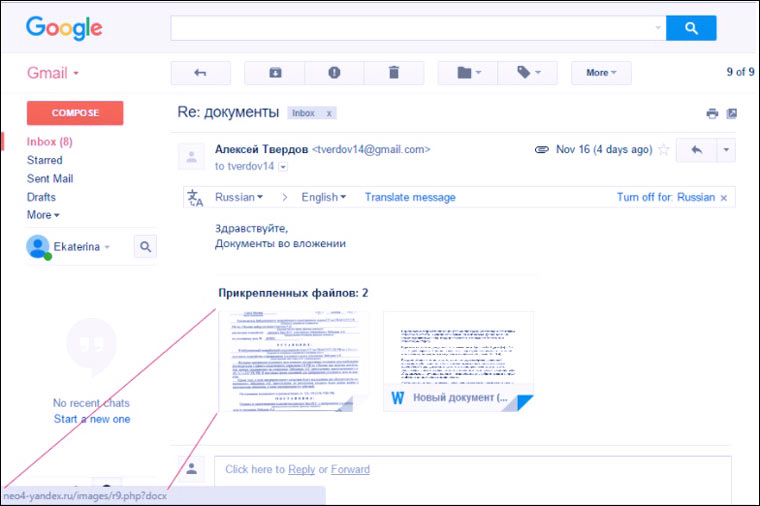
Некоторые люди получают десятки деловых писем с документами в течении рабочего дня. С такой нагрузкой можно легко повестись на метку «Re:» в теме письма и забыть про то, что с этим человеком вы пока не переписывались.
Особенно, если в поле отравитель указано «Александр Иванов», «Екатерина Смирнова» или любое простое русское имя, которые абсолютно не задерживаются в памяти человека, постоянного работающего с людьми.
Если целью мошенников является не сбор SMS-платежей за разблокировку винды, а принесение вреда конкретной компании, то письма с вирусами и фишинговыми ссылками могут рассылать от имени реальных работников. Список сотрудиков можно собрать в соцсетях или посмотреть на сайте компании.
Если человек видит в ящике письмо от человека из соседнего отдела, то он к нему особо не присматривается, может даже проигноривать предупреждения антивируса и открыть файл несмотря ни на что.
4. Письма от «Google/Яндекс/Mail»
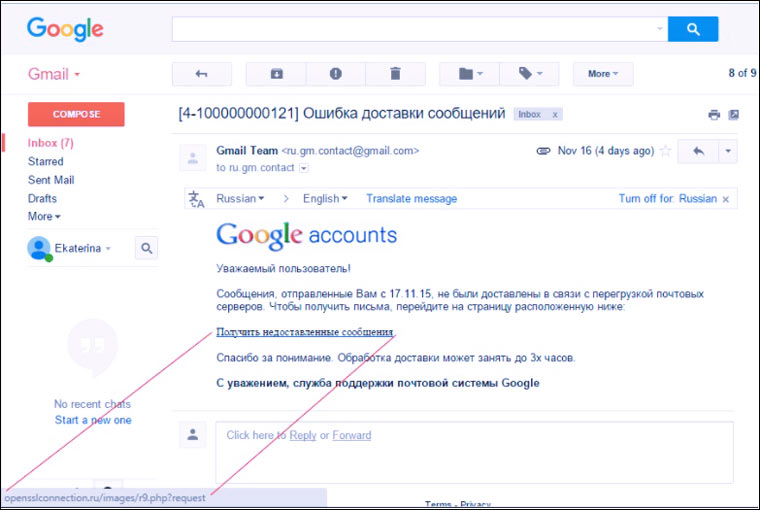

Google иногда присылает письма владельцам ящиков Gmail о том, что кто-то пытался зайти в ваш аккаунт или о том, что закончилось место на Google Drive. Мошенники успешно копируют их и заставляют пользователей вводить пароли на подставных сайтах.
Фальшивые письма от «администрации сервиса» также получают пользователи Яндекс.Почты, Mail.ru и прочих почтовых служб. Стандартные легенды такие: «ваш адрес добавлен в черный список», «срок действия пароля истек», «все письма с вашего адреса будут добавляться в папку спам», «посмотрите список недоставленных писем». Как и в трех предыдущих пунктах, основными оружиями преступников являются страх и любопытство пользователей.
Как себя защитить?
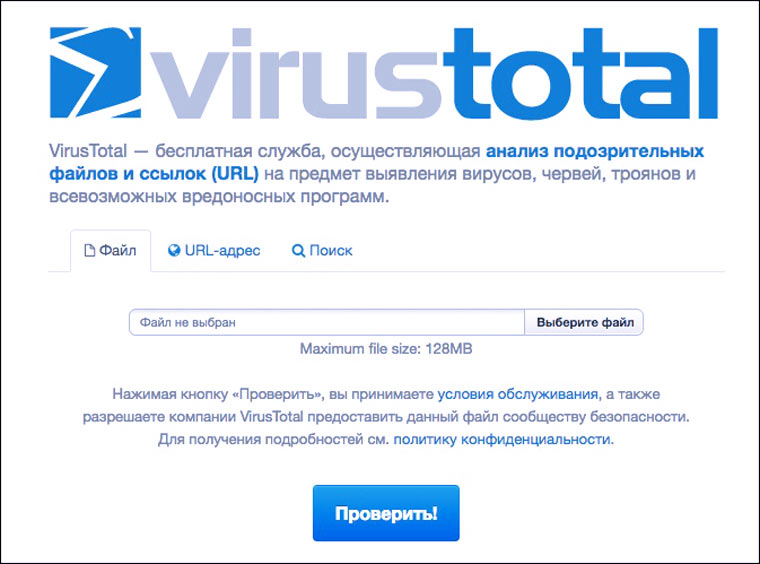
Установите антивирус на все свои устройства, чтобы он автоматически блокировал вредоносные файлы. Если вы по каким-то причинам не хотите им пользоваться, то проверяйте все хоть немного подозрительные почтовые вложения на virustotal.com
Никогда не вводите пароли вручную. Используйте менеджеры паролей на всех устройствах. Они никогда не предложат вам вариант паролей для ввода на подставных сайтах. Если по каким-то причинам вы не хотите их использовать, то вручную набирайте URL страницы, на которой собираетесь вводить пароль. Это касается всех операционных систем.
Везде, где это возможно подключите подтверждение пароля по SMS или двуфакторную идентификацию. И конечно, стоит помнить о том, что незнакомым людям нельзя посылать сканы документов, паспортные данные и переводить деньги.
Возможно многие из читателей при взгляде на скрины писем подумали: «Я что дурак файлы из таких писем открывать? За километр видно, что это подстава. Я не буду парится с менеджером паролей и двуфакторной идентификацией. Я просто буду внимательным».
Да, большую часть мошеннических писем можно разоблачить на глаз. Но это не касается случаев, когда атака направлена конкретно на вас.
Самый опасный спам - персональный

Если ревнивая жена захочет почитать почту мужа, то Google предложит ей десятки сайтов, которые предлагают услугу «Взлом почты и профилей в соцсетях без предоплаты».
Схема их работы проста: они отправляют человеку качественные фишинговые письма, которые тщательно составлены, аккуратно сверстаны и учитывают личные особенности человека. Такие мошенники искренне стараются зацепить конкретную жертву. Выясняют у заказчика ее круг общения, вкусы, слабые места. На разработку атаки на конкретного человека может уйти час или более, но усилия окупаются.
Если жертва попадается, то отправляют заказчику скрин ящика и просят оплатить (средняя цена около $100) свои услуги. После поступления денег высылают пароль от ящика или архив со всеми письмами.
Часто бывает, что когда человеку приходит письмо со ссылкой на файл «Видео компромат на Таню Котову» (скрытый кейлоггер) от своего брата, то наполняется любопытством. Если письмо снабдить текстом с подробностями, которые известны ограниченному кругу лиц, то человек сразу отрицает возможность того, что брата могли взломать или им притворяется кто-то еще. Жертва расслабляется и отключает антивирус к чертовой матери, чтобы открыть файл.
К подобным услугам могут обращаться не только ревнивые жены, но и недобросовестные конкуренты. В таких случаях ценник выше и методы тоньше.
Не стоит надеяться на свою внимательность и здравый смысл. Пусть на всякий случай вас страхуют безэмоциональные антивирус и менеджер паролей.
P.S. Зачем спамеры пишут такие «тупые» письма?

Тщательно подготовленные мошеннические письма - относительная редкость. Если зайти в папку спам, то можно повеселиться от души. Каких только персонажей не придумывают мошенники для вымогательства денег: директор ФБР, героиня сериала «Игра Престолов», ясновидящий, которого к вам направили высшие силы и он хочет поведать тайну вашего будущего за $15 долларов, киллер, которому вас заказали, но он душевно предлагает откупиться.
Обилие восклицательных знаков, кнопки в теле письма, странный адрес отправителя, безымянное приветствие, автоматический перевод, грубейшие ошибки в тексте, явный перебор креативности - письма в папке спам просто «кричат» о своем темном происхождении.
Почему мошенники, которые рассылают свои послания миллионам адресатов, не хотят потратить пару часов на составление аккуратного письма и жалеют 20 баксов на переводчика, чтобы увеличить отклик аудитории?
В исследовании Microsoft Why do Nigerian Scammers Say They are from Nigeria? глубоко анализируется вопрос «Почему мошенники продолжают посылать письма от имени миллиардеров из Нигерии, когда про «нигерийские письма» широкой общественности известно уже лет 20». По статистике, более 99.99% получателей игнорирует такой спам.
Заблудиться можно не только в лесу, но и в онлайне. И тому виной может стать неверный путь или адрес, ведущий к ресурсу. Вы не знаете, что такое URL адрес? Тогда прежде, чем пускаться в дальнейшее путешествие по виртуальному пространству, давайте разберемся с системой электронных адресов.
Что такое URL
URL является общепринятым стандартом записи адреса и указания на расположение ресурса в интернете. С английского его название (Uniform Resource Locator ) переводится как единый указатель ресурсов. Можно встретить более раннюю расшифровку аббревиатуры URL — Universal Resource Locator (универсальный локатор ресурсов ). Но оба значения скорее дополняют понятие URL , чем перечат друг другу.
Основной формат записи структуры URL адреса выглядит так:
://:@:/?#
— чаще всего имеется в виду протокол.
логин
– логин пользователя, используемый для авторизации на ресурсе.
пароль
– пароль пользователя для авторизации.
хост
– доменное имя хоста.
порт
– порт хоста, используемый во время подключения.
URL
– путь, по которому находится запрашиваемый ресурс на сервере.
параметры и якорь
– значение переменных и идентификатор на определенном ресурсе.
Передача значения переменных в строке запроса возможна лишь с помощью метода GET .
Рассмотрим формат URL
адреса страницы запрашиваемого ресурса на практических примерах. На клиентской стороне URL отображается в адресной строке браузера:
Чаще всего встречаются такие варианты:
- http:// ru.wikipedia.org/wiki/Заглавная_страница – для передачи запроса используется http (протокол передачи гипертекста );
- https://ru.wikipedia.org/wiki/Заглавная_страница — в качестве способа передачи используется https . Является защищенной формой протокола http , использующего шифрование (SSL или TLS );
- fttp://wikipedia.org/wiki/file.txt – протокол передачи файлов fttp ;
- http://mail.ru/script.php?num=10&type=new&v=text – передача значений переменных в строке запроса с помощью метода GET .
Любой формат URL адреса представляет собой, прежде всего, символьную строку. В ее состав могут входить:
2; Латинские буквы.
2; Арабские цифры (0-9).
2; Зарезервированные символы («+», «=», «!» и другие).
2; Специальные символы – на них остановимся более подробно.
Использование специальных символов в URL
Конечно, таких уж слишком «специальных» символов в URL не используют. Но несколько есть:
- ? – служит для отделения в строке запроса блока с передаваемыми параметрами;
- & — отделяет передаваемые параметры друг от друга;
- = — отделяет в параметре переменную от ее значения;
- : — служит для отделения протокола от остальной части URL;
- # — символ используется в локальной части адреса. Позволяет обратиться к определенной части запрашиваемой страницы;
- @ — указывается в регистрационных данных пользователя и при передаче данных с помощью протокола mailto.
Но все это лишь теория. Поэтому перед тем, как узнать остальное, рассмотрим небольшой практический пример.
Наглядный пример
Возьмем для наглядности вот такую простую форму регистрации:
Вот ее код:
Форма регистрации
Первой строкой в начале формы мы прописали для нее файл обработчика (php)
и метод передачи данных через URL
адрес сервера:
Теперь приведем код файла обработчика (1.php)
:
Ваш Ник:".$_GET["nick"]."
"; echo "Ваш возраст:".$_GET["age"]."
"; ?>Введем данные в форму и отправим их для обработки на сервер. Вот что мы получим в итоге:
Обратите внимание на формат URL
в адресной строке на первом скриншоте. После введения данных и нажатия на кнопку «Отправка данных
» значения всех полей отправляются для обработки на сервер. А нас перенаправляет на страницу 1.php
, где размещен код обработчика.
Перед тем, как посмотреть на результат обработки, взгляните на адресную строку на втором рисунке. В ней отображаются значения полей, переданных на обработку с помощью метода GET.
Для того чтобы скрыть данные, отправляемые на сервер, используется метод POST. Тогда приведенный выше URL будет выглядеть следующим образом:
http://localhost/home/1.php .
Формат URL адресов на сайтах
Чаще всего на сайтах используется древовидная система URL . То есть правильный URL адрес состоит из нескольких вложенных друг в друга элементов, последний из которых и является нужной веб-страницей.
Для наглядности возьмем конкретный URL , являющейся одним из разветвлений адреса нашего сайта:
https://www..html
Разберем его по частям:
- www.сайт – эта часть является доменным именем сайта. Если набрать его в адресной строке браузера, то оно выведет на главную страницу сайта. В большинстве случаев это файл index. html ;
- templates – данная часть адреса указывает на определенный раздел сайта. В нашем случае это раздел с шаблонами;
- page_2.html – является конечным элементом URL , ведущего на веб-страницу тематического раздела ресурса.
Чаще всего URL адреса основных разделов полностью отображают карту сайта. Но не все так просто обстоит с переадресацией на сайтах, развернутых на основе популярных движков (CMS ).
Особенности построения URL в WordPress
В WordPress , как и в любом движке, построенном на php , генерация всех страниц сайта происходит динамически. То есть одна часть берется из одного шаблона, другая генерируется «на лету » на основе нескольких.… Но такая летучесть имеет один существенный недостаток – наличие кусков передаваемых параметров в URL .
Причем это ущемляет не только эстетическую составляющую отображения адресов, но и неоднозначно воспринимается поисковиками. А это может негативно влиять на продвижение сайта:
Поэтому лучше использовать на своем сайте чистые URL
адреса. Но где взять их, если CMS
система не предусматривает возможности их редактирования.
Чистые URL – это адреса, не содержащие в себе передаваемых параметров (в случае с WordPress – элементов запросов к базе данных), а лишь путь к документу. То есть https://www..html является примером чистого URL.
Самый простой способ настройки отображения URL в WordPress – это использование специализированных плагинов.
: всегда хотел это понять, но значимость его была настолько мала, что всегда находился повод этого не делать:)
А вы задавались вопросом: URL — что это ?
Всегда с таким сталкиваюсь, но до сих пор не желал понять в чем различие между терминами URI, URL, URN, а тут вдруг постик (к сожалению, он уже канул в Лету), решил - и сам почитаю, и другим поведаю, хотя, как сказано выше, от этого ничего не изменится, но люблю я иногда побуквоедствовать, так-что читайте толковый переводец:
Вы когда-нибудь обращали внимание на адресную строку в Вашем браузере? Что это? URI, URL или URN? Многие из нас не делают различий между URI, URL, URN, а кое-кто даже и не слышал терминов URI и URN, все просто пользуются термином URL. Давайте вместе попытаемся разобраться в этом.
Расшифровка аббревиатур
URI - Uniform Resource Identifier (унифицированный идентификатор
ресурса)
URL - Uniform Resource Locator (унифицированный определитель местонахождения
ресурса)
URN - Unifrorm Resource Name (унифицированное имя
ресурса)
Внимание, здесь в мелочах кроется истина, но пока ничего не понятно, какая-то каша. Едем дальше.
Определение
URI: Обозначает имя и адрес ресурса в сети. Как правило, делится на URL и URN, поэтому URL и URN это составляющие URI.
URL: Адрес некоторого ресурса в веб. URL определяет местонахождение ресурса и способ обращения к нему.
URN: Имя некоторого ресурса в веб. Смысл URN в том, что он определяет только название конкретного предмета, который может находится во множестве конкретных мест.
Нет ничего лучше, чем конкретный пример
URI = http://сайт/2009/09/uri-url-urn.html
URL = http://сайт
URN = /2009/09/uri-url-urn.html
Подведем итоги
URI это концепция абстрактного идентификатора, тогда как URL и URN конкретная реализация - адреса и имени.
Надеюсь всем всё понятно. Будьте грамотны!
Восприятие каждого из нас индивидуально, поэтому — спорьте и читайте обсуждения в комментариях к статье, там много чего интересного.
У пользователей нередко возникают вопросы, что такое URL-адрес файла (сайта), как узнать его и в чем ценность такого реквизита. Наша статья даст необходимые ответы.
Что такое URL
Uniform Resource Locator расшифровывается как «указатель местонахождения сайта в Сети». URL-идентификатор состоит из доменного имени и пути к определённой странице с названием её файла. Изобретателем URL-адреса был член Европейского совета по ядерно-военным проблемам, заседающего в Женеве, Тим Бернерс-Ли. На момент своего создания в 1990 году URL сайта – это просто адрес в системе, по которому находится файл. Чтобы узнать URL сайта, достаточно заглянуть в адресную строку, а для определения адреса файла необходимо перейти в контекстное меню, нажав на соответствующем объекте правую кнопку мыши. Обладая множеством преимуществ, в частности доступностью навигации в Сети, такой адрес имеет и недостаток – способность работать исключительно с латиницей, некоторыми символами и цифрами. При необходимости использования кириллицы проводится специальная перекодировка.
Разновидности URL
Статический – не предполагает изменений на странице.
Динамический URL – что это, можно понять, если представить поисковую форму или другой навигационный инструмент, в котором информация генерируется в зависимости от поступающих запросов.
Адрес с идентификатором сессий, который добавляется каждый раз, когда пользователи посещают страницу.
Значение URL в SEO-продвижении
Поисковики учитывают ключи, входящие в URL. Больше всего влияют на поисковое продвижение ключевые слова в домене и поддоменах.
Если адрес сайта информативен, это также повышает рейтинг. Поисковый робот с большой вероятностью выдаст его в ответ на тематический запрос.
URL, который соответствует запросу, выделяется в поисковой выдаче жирным шрифтом, привлекая дополнительное внимание и повышая кликабельность.
Рекомендуем также
 Виды смайликов и их значение
Виды смайликов и их значение
 Настройка подключения в Putty и WinSCP Winscp перенос настроек
Настройка подключения в Putty и WinSCP Winscp перенос настроек
 Be-on-Road – бесплатный оффлайн GPS навигатор Карты для be on road 3
Be-on-Road – бесплатный оффлайн GPS навигатор Карты для be on road 3
 Как самому изменить имя в ВК: подробная инструкция для смены
Как самому изменить имя в ВК: подробная инструкция для смены
 Steam client not found — что делать и как исправить сбой Что за ошибка steam client not found
Steam client not found — что делать и как исправить сбой Что за ошибка steam client not found
 Acrobat reader редактирование pdf
Acrobat reader редактирование pdf